沉默的百万token对话:英伟达Agent模型如何突破智能边界
在数字世界的深处,智能体正面临着一场关于“记忆”与“执行”的生存考验。当复杂任务要求模型在百万级token的上下文窗口中精准捕捉逻辑脉络时,传统的计算架构往往陷入性能枯竭的困境。英伟达最新推出的Nemotron3Super模型,正是为了破解这一瓶颈而生,通过重构智能体的思维路径,试图在无限增长的数据海洋中建立起稳定的导航系统。
智能体面临的计算困境
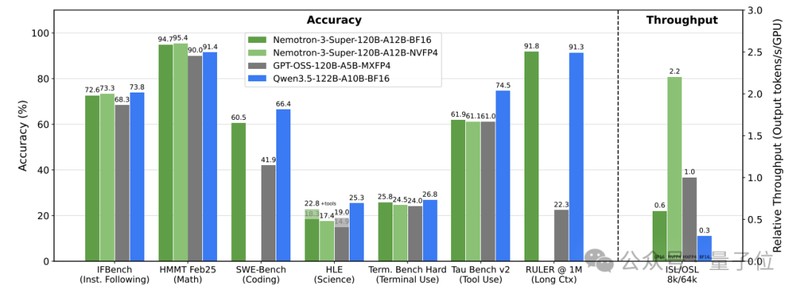
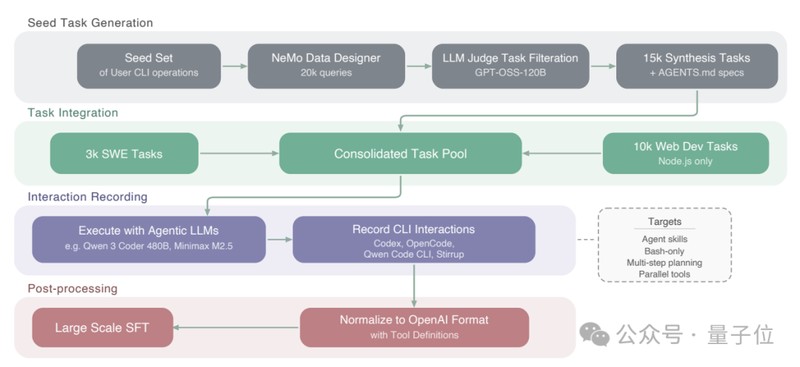
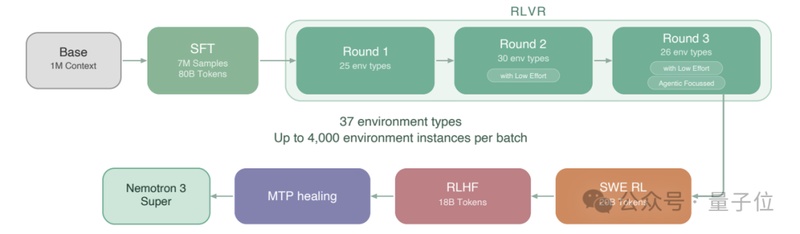
长期以来,人工智能模型在处理长程任务时,容易在海量信息中迷失方向,导致推理偏差或执行效率低下。智能体不仅需要理解静态文本,更需在动态的终端操作环境中进行决策。从航空调度到零售物流,复杂的业务流要求模型具备极高的逻辑完整性。Nemotron3Super通过两阶段训练工艺,有效解决了长输入场景下的性能降级问题,确保模型在处理海量信息时依然能输出精准的指令,将复杂的终端交互知识内化为原生技能。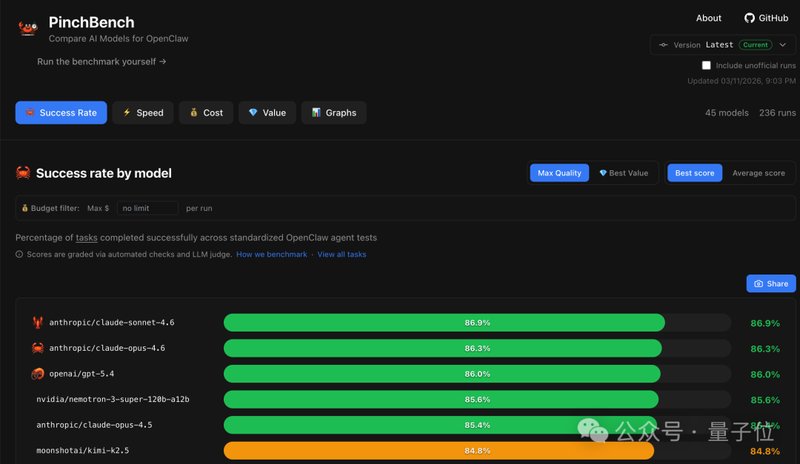
混合架构的逻辑重构
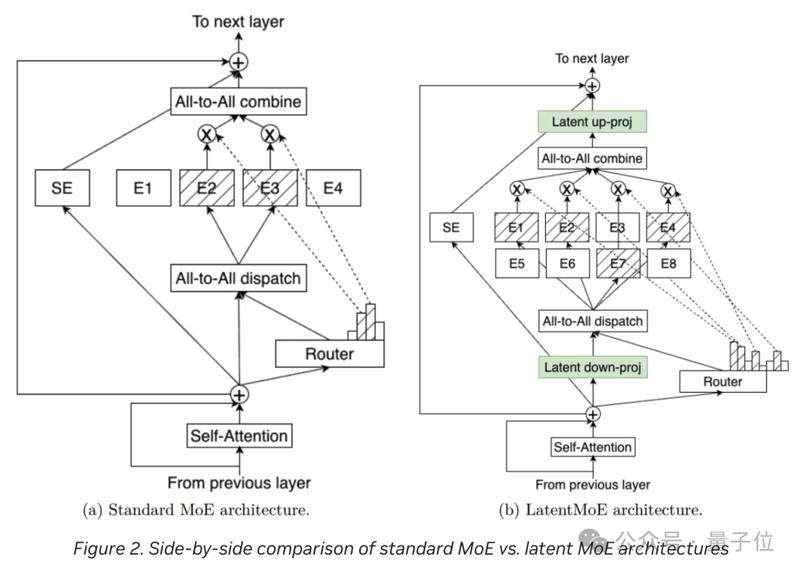
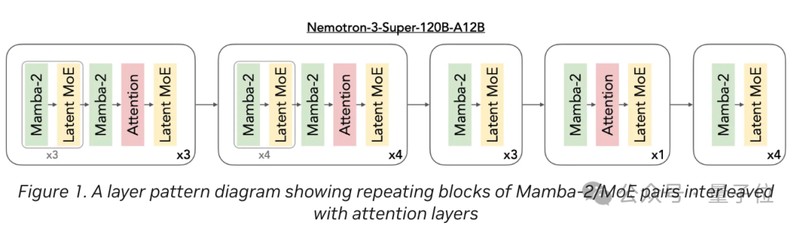
为了在混沌的计算环境中寻找秩序,该模型采用了Mamba-Transformer混合架构。这不仅仅是技术的堆叠,更是一种对计算效率的深刻洞察。Mamba-2层以线性时间复杂度处理长序列,如同为模型装上了高效的过滤器,而Transformer全局注意力层则作为核心引擎,确保了关键逻辑的稳固。这种架构上的平衡,使得模型在执行多步工作流时,能够通过PivotRL技术在不确定性较高的决策点进行重点强化,有效遏制了推理漂移风险,实现了从单纯的“预测下一个词”到“执行复杂任务”的质变。
重塑硬件定义的未来
当260亿美元的资金投入到开源模型构建中时,其背后的意图已超越了单一产品的发布。这是对未来算力范式的预演。通过在自家的超级计算机集群中进行极限拉练,英伟达正试图通过软件实操来定义硬件的进化路线。这种由软件定义硬件的策略,将模型训练过程中沉淀的宝贵数据直接反哺至硬件架构规划。对于全球开发者而言,这意味着未来将拥有一个更加稳固、高效且透明的底层底座,从而在这一由开源生态驱动的算力森林中,探索出更多超越既有逻辑边界的智能应用可能。